Data Entry Methods
A phonetic mapping method
This method is uniform across all the languages since data entry is based on the sounds of the Aksharas. Thus if you know how to type in say, Bengali, you will automatically be able to type in other languages. The basic Aksharas (Vowels and Consonants), are mapped to phonetically equivalent Roman letters where such equivalents can be identified . Also, each vowel and consonant in a language is mapped to a unique key. Besides the vowels and consonants, special symbols required for a language are also included. For most languages, up to thirteen punctuation marks are included so as to permit easy preparation of texts conforming to modern day publishing requirements.
Phonetic approach to Data Entry
Data entry using the phonetic input scheme of the IITM software is uniform across all languages and the key mapping shown below applies. The aksharas are shown in Devanagari for illustration. What is seen in Devanagari is common to all the scripts. The assignment for aksharas unique to Tamil, Telugu or Bengali is also seen in the mapping.Keyboard Mapping for the Phonetic input method

It will be observed that this mapping allows the entry of 16 vowels, 42 consonants, 4 special consonants, 16 special characters and 10 numerals. With this mapping approximately 12000 different syllables may be formed.Data entry in any of the Indian Languages is accomplished using the method discussed below. The general principle relating to the entry of conjunct characters in a syllabic writing system is also discussed below.
The IIT Madras software supports sixteen vowels and forty six different consonants. Though most languages do not have beyond 36 consonants, the above number applies to the superset of all the consonants across all the Indian Languages. Four of the forty six are used for generating the special characters required in applications dealing with Vedic texts, Music notation etc.. A detailed discussion of the four will be found in the local language document dentry.llf supplied with the Editor package.
The data entry scheme followed conforms to the formation of syllables which are essentially a combination of one or more consonants and a vowel. The term "akshara" is synonymous with a syllable. Aksharas with more than one consonant in them are generally known as conjuncts or consonant clusters. The term "Samyuktakshar" is used to refer to such combinations. In India, the basis for any language has always been the akshara and all writing systems in use employ schemes for writing syllables rather than a mere sequence of consonant and vowel shapes. The IIT Madras software is based on the principle of syllables. The editor application will allow the entry of a pure vowel, a basic consonant combining with one of many different vowels as well as conjuncts with two or three consonants with a vowel.
Mapping scheme shown as a table

Details pertaining to the mappings are discussed below.
The Devanagari script is used for illustration. Where required, scripts from other languages will be seen. The table shown above will serve as a useful reference at different places within this document.
There are thirteen vowels in Devanagari. In older manuscripts three other vowels are seen but the IITM system does not support them as vowels. It allows them to be typed in as special aksharas. Each of the consonants can combine with every one of the vowels and the combinations are indicated through Matras. In other words, what one normally understands as the medial vowel representation, refers to the method used to write a consonant vowel combination. In most Indian languages, a vowel by itself will not be seen in the middle of a word (though there are many exceptions to this rule).
The last but one combination in the above illustration is not reckoned as a Visarg (since a Visarg may also follow a consonant vowel combination). Here the Visarg is treated as a vowel. The Visarg when used in this fashion is reckoned as the fifteenth vowel. The Anuswar is also treated as a vowel though one will often find it following a consonant vowel combination. In such situations, a special symbol representing the Anuswar is used. This will be explained later. The Anuswar is reckoned as the fourteenth vowel.The ordering of the vowels and assigning them a numeric (positional) value has been done according to general conventions but since the superset of vowels across all the languages includes more than what is seen above, the numerical assignments may appear a bit arbitrary.
The Vowels are mapped as shown in the table above. The mapping for vowels corresponds to the vowels of the Roman alphabet for the basic vowels. The long vowels are mapped to the capitals of the corresponding short ones. Six of the vowels are mapped using other keys.
The two short vowels in the Southern languages are not supported in Devanagari and in the earlier version of the Editor they could not be entered from the keyboard when using Sanskrit, Hindi etc. The second version of the Editor allows this however. The transliteration of these two vowels into the Devanagari derived scripts has not been standardized but specific shapes have been assigned for Hindi and Gujarati. In these languages, the vowels correspond to new vowels introduced into the language to reflect the sounds of the vowels in words such as "way" and "doctor".
Consonants
The first twenty-five consonants are common to most of the languages (except Tamil). They are mapped as shown in the above figure.The eight consonants from the group of semivowels and sibilants are mapped to the nearest Roman letter. The other consonants in the set come from different languages. These have been mapped somewhat arbitrarily for want of a proper Roman equivalent.It may be observed that the basic vowels and consonants have been arranged according to the normal ordering seen in Indin languages. This has been done specifically to permit clean lexical ordering for text processing purposes.
Special Symbols
The following special symbols are supported, though they might not have been implemented for each language.
The anuswar and chandra bindu. These are mapped to ' and " respectively. These may not seen immediately on screen as they are typed in since they are written on the previously typed akshara. But they can be seen by minimizing and restoring the window of the Editor. The window of the Editor may also be resized if required.The viram, (period sign or the full stop) is mapped to the ASCII period symbol itself , i.e., "." . In some scripts, an explicit 'Danda' may be required. That is typed in as :@ (Visarg followed by @).
Double or poorna viram is typed in as : followed by q.
The avagraha sign is mapped to { . This sign is used in early Sanskrit texts.
The question mark is mapped to the ? key itself.
The "Om" symbol is mapped to the carat key ^ .
Special ConsonantsThere are four special consonants. These are,
A consonant to represent Urdu extensions to some Devanagari characters which have a dot below them. This also serves as a special consonant and is mapped to Q. This consonant when combined with consonants such as 'ka' 'ja' etc., produces the Urdu equivalents of the respective letters. This is also used to form Virtual syllables with the basic consonants to provide the equivalents of "half forms". A virtual syllable has the same linguistic value as its real equivalent but provides an alternate display for the sound. In other words, ligatures representing half forms may be typed in as virtual syllables without losing their linguistic value in terms of internal coding/representation.
A consonant representing the visarg is mapped to the colon ":" and this consonant is used for typing in special letters and some of the vowels and consonants not directly included in the basic set of sixteen vowels. These include two special vowels in Hindi (basically to deal with the equivalent of the English "a" as in ' way' ), the three vowels of Sanskrit (vocallic r , vocallic l and its long form) which are used mostly in older manuscripts.
A consonant to deal with music notation is mapped to "&" and is useful for producing documents featuring the notation recommended for Carnatic Music (Classical Music of South India). This consonant is also used for generating additional symbols which represent specific Braille characters such as Mathematical comma, decimal point etc.
A consonant to deal with Vedic symbols is mapped to ^. This is used to generate the accent marks used in Yajur Vedic texts. Sama Vedic notation is also supported if the Grantha Script is selected for data entry. By itself this key would produce the "Om" symbol but when followed by other vowels, will be used to generate the Vedic accents.
NumeralsNumerals may be input either in local language or in Roman. In local language they are displayed in their native form specific to each language. This dual mode of representing numerals has been provided to cater to situations involving old manuscripts where the numerals were always written in their native form. Modern writing in Indian languages tends to utilize Roman numerals. It is possible to use appropriate fonts and obtain the Roman form for the numerals typed in local scripts. However, the editor always permits data entry of Roman numerals and this may be adequate in practice.
Standard punctuation marks
The following punctuation marks are supported directly and can be entered as local language punctuation marks. The key mappings are the same except for the exclamation mark, which is mapped to the Pipe Symbol. (The exclamation mark itself is used for typing in the short vocallic 'r') There are 13 symbols in this set. These marks are viewed as special syllables and are distinguished from their ASCII counterparts internally. Data entry of texts in different languages becomes easier with this scheme since one can type the punctuation just as in regular data entry using the same keys.. , ? / ; ! = + - ( ) * `
The full complement of punctuation symbols is available by switching the keyboard to the English mode of data input (See below). The advantage of using local language punctuation symbols will become apparent when string processing is attempted on local language text.
The rules are given below. The figure following the text shows examples.
Please note that the 'control' key is used here. Users of Microsoft Windows will find this a bit confusing initially because the control key is generally used for invoking the menus or commands. The choice of the control key has been effected to make sure that data entry rules will remain the same across all multilingual applications (and across platforms), developed using the IITM software).
- A vowel by itself is generated by typing in the assigned key.
- A consonant by itself is generated by typing in the assigned key.
- Any consonant vowel combination is typed in by entering the consonant first and then the vowel key.
- A conjunct is formed by successively typing in the consonants forming the conjunct and using the Ctrl key to indicate that the consonants should combine.
The IITM system allows only up to three consonants to combine in this fashion. This is a limitation in the present version of the Editor. However, almost all the conjuncts seen in practical use, as well as in older manuscripts have been provided for in the software. It must be observed that the IITM system will not permit arbitrary formation of arbitrary conjuncts. The ltest.llf file included with the distribution gives the list of supported conjuncts. Conjuncts not seen in the list are not ruled out but may be typed in differently (see below). The ltest.llf file is supplied without a header so that one may open it in the specified default language.
Independent vowel inside a word.
Should a vowel be required to stand out separately from a consonant preceding it, the Ctrl key may be used, i.e., you press the Ctrl key along with the key for the Vowel.
(This feature is very useful for typing in many words in Gujarati and Tamil)
Conjuncts involving "ra"
The consonant "ra" combines with almost all the other consonants and several other conjuncts. For any given consonant, the IITM system permits a maximum of 31 conjuncts (as can be seen in the ltest.llf file mentioned above.
However conjuncts formed with "ra" are many more in practice ( "ra" combines with almost all the consonants and many other conjuncts as well. To accommodate this larger number the consonant "ra" is assigned two different letters, r as well as R. Use of r will allow conjuncts to be formed with other consonants up to "da" . R will have to be used to form conjuncts with consonants after "da" i.e., "dha" and after.
The ltest.llf file giving the list of samyuktakshars shows two separate groups for "ra". The first is typed in with "r" while the second with "R". This file is included with the Editor package.
The text below explains the methods with suitable examples.
Typing in arbitrary conjuncts using half lettersThe IITM system allows half letters to be typed in. (A feature useful for Devanagari and other North Indian Languages) One can type in the half form of a consonant (applicable for all consonants with a vertical stroke) in the following manner. First type in Q and follow it with Ctrl and the consonant whose half form is desired. Also you must add a halanth to make the akshara conform to linguistic requirements.
The special consonant Q will generate the Matra for a vowel when the vowel is keyed in after Q. This way a variety of syllables may be displayed just be building up the required shapes using Q.Half forms are not strictly defined for some characters, especially the ones which have retroflex sounds in the palatals group. For some consonants, the half form may be shown in reduced form. In building up conjuncts with half forms one may be able to display many four and five consonant conjuncts. It must be remembered however that the important difference here is in the number of bytes used to show the conjunct. The IITM system uses a two byte internal representation for conjuncts typed in as per (4) above but conjuncts built with half forms occupy two bytes for every half letter.
In respect of the Southern Languages, the equivalent of the half form is a representation of the consonant either in the upper part of the syllable or the lower part depending on the order of the consonant in a syllable. Usually, the first consonant (except for "ra") is shown at the top while the succeeding ones are shown directly below the first or in many cases shifted to the right and shown below. The file peculiar.llf included with the package is a good reference for understanding the different conventions followed for the Indian scripts.
Keying in special characters:There is provision for typing in Vedic symbols as given by the scheme below. A vedic symbol is viewed as a special combination of a vowel with the Vedic Consonant. The four symbols in the Yajur Veda are obtained by combining the Vedic consonant with four vowels. The carat ^ key is assigned to the Vedic consonant.
To start a Vedic symbol type the carat ^. This will print the "Om" symbol.
^ A This is the AnudatamDetails of Vedic accent marks are not given here, for such information will be of use only to a few.
^ i This is the Swaritam
^ I This is the Dheerga Swaritam
^ u This is the kampa or kampitamAs in the case for Bindu and Chandra-bindu, these characters are not seen immediately on the screen while typing. They can be seen by minimizing the Editor window and restoring it back. They may not be displayed immediately when the key sequence is entered since the overlapping symbols will apply to the previously entered akshara. There is also provision for keying in music symbols, but the required font has not been incorporated into this version of the Software.
Data entry for English TextThe Editor permits normal English text to be typed in at any time by changing the mode of input from local language to English. This is achieved by using the Function Key F9. English characters are part of the character set supported by the IITM software and hence there is no need to specify English as another language. The choice of the font used for English is fixed as of now and is Times New Roman.
F9 functions as a toggle switch between the two modes of input. So when the keyboard is in the local mode, pressing F9 would change it to English input and vice versa.
The small bar at the bottom of the Editor window will indicate the current mode of input. Please note that sometimes it may take a few seconds for the bar to change after F9 is pressed. It will therefore be a good idea for one to press F9, wait for the change in the indicator bar and then proceed.
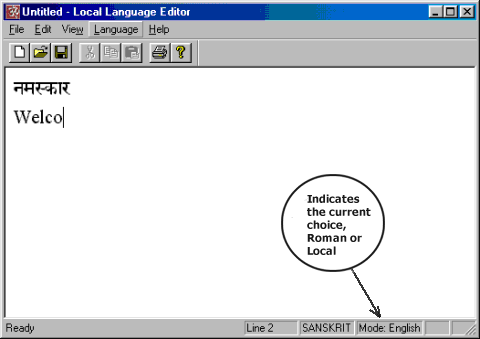
The Editor is thus bilingual even if only one Indian language is used for data entry. The English input mode permits one to prepare a document incorporating a commentary or interpretation in respect of some text in Indian language through English. This facility will be of great help in preparing reports and dissertations in English, which are also required to display Indian language text.A very useful feature of the application is in generating an HTML document to be served on the web. One can simply type in the HTML text in English along with text in any other Indian language and use the converter program to generate the final HTML document. More information on this is provided in a separate document distributed with the package.
Phonetic Mapping
Basic Rules for Data Entry
Vowels
Consonants
syllables
Special Consonants
Punctuation Marks
English Text